Doma Rubin (LSST)
The Rubin Observatory (LSST) exercise is an ongoing activity to evaluate PanDA as both a workflow and workload management system. A workflow graph is dynamically generated by Rubin middleware for each payload submission and includes, among others, a set of dependencies for each individual job that must be satisfied before the job could be processed. A single workflow can consist of a hundred thousand jobs forming the vertexes of a DAG. It is the first use case of the DG-based workflow support in iDDS. Every workflow is mapped to sequentially concatenated Work objects in iDDS. iDDS also allows Work objects to be incrementally released based on messaging, in order to avoid long waiting in each Work.
iDDS Rubin flow
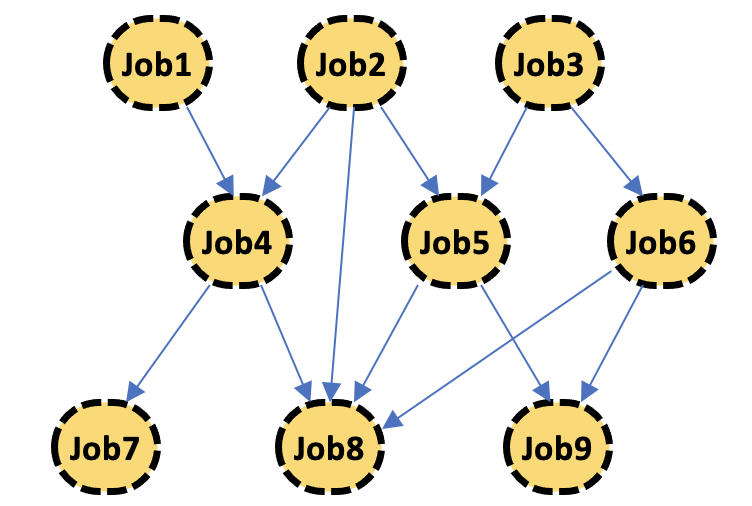
Rubin at the beginning is DAG in jobs level. It’s different iDDS Task level DAG. In iDDS Task level DAG, when a task generates new output files, it triggers to generate new jobs in the following tasks with these new inputs. iDDS Rubin is job level DAG. At the beginning, all jobs and their relations are defined.
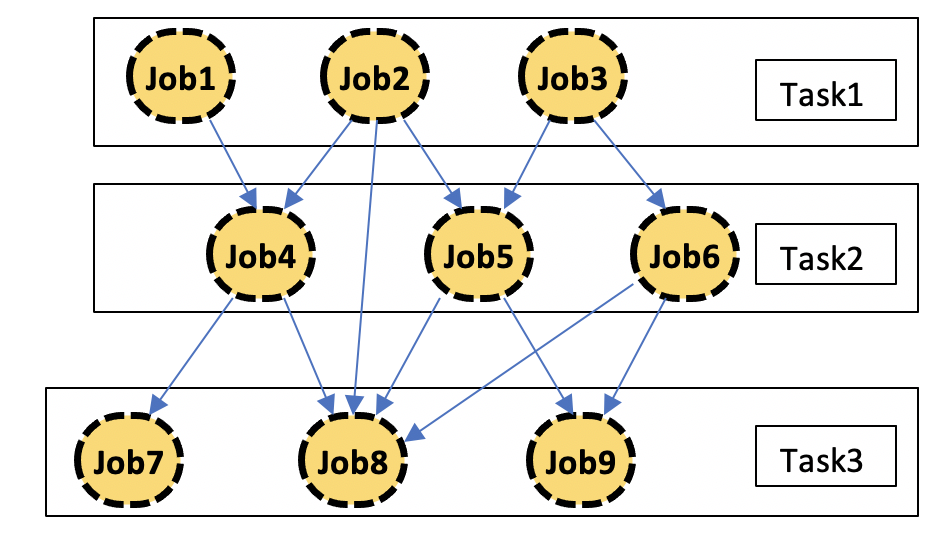
To adapt the PanDA and iDDS task management, the client organizes jobs and splits jobs into different tasks based on their dependencies (https://github.com/lsst/ctrl_bps/blob/master/python/lsst/ctrl/bps/wms/panda/idds_tasks.py). The dependency map is transferred to iDDS, for every task. iDDS maps the dependency to inputs and outputs of jobs. The inputs of a job are its dependencies. So at the beginning, all jobs are defined. iDDS needs to release the jobs when all inputs for a job is ready. To efficiently release jobs, iDDS improves the inputs and outputs management. iDDS adds a trigger system to release jobs, instead of checking whether all inputs are ready for every job.